DUSt3R#
DUSt3R은 네이버랩스에서 개발한 모델로 2D를 3D로 변경해주는 AI도구입니다. Transfomer의 encordor과 decoder을 사용하여 개발되었습니다.
논문 introduction의 suummary를 보면 4가지의 이점에 대해 소개합니다.
End-To-End 3D reconstruction
pointmap representation for MVS applications
optimization procedure to globally align pointmaps
performance on a range of 3D vision tasks
연관된 기술에는 SFM, MVS, Direct RGB-to-3D, Pointmaps 등이 있습니다.
SFM
Structure From Motion의 약자로 동일한 객체를 다른 시점에서 중첩되도록 찍은 Multi-view 이미지들로 부터 3D Structure와 Camera pose를 복원하는 프로세스이다.
4가지 조건이 잘 충족되지 않으면 3D reconstruction결과가 좋지 않음.
MVS
Multi-view stereo의 약자로 서로 다른 시점을 가진 2개 이상의 이미지를 이용해 해당 이미지에 나타나는 물체들의 3D 표면을 복원하는 프로세서입니다.
Method#
과정을 보면 가장 먼저 pointmap의 경우 3D point의 2D filed dense를 포인트맵을 \(X ∈ \mathbb{R}^{W×H×3}\) 으로 나타내고 해상도 W × H 이미지(I)에 대해 X는 이미지 픽셀과 3D 점 사이의 일대일 매핑을 형성합니다.\(I_{i,j} ↔ X_{i,j}\) 모든 픽셀 좌표에 대해 \((i, j) ∈ {1 . . . W} × {1 . . . H}\) 으로 나타낼 수 있습니다.
여기서 각 카메라 광선이 모든 3D포인트에 도달하는 것을 가정으로 진행. 불투명한 표면의 경우는 무시됨.
camera의 경우 \(K ∈ \mathbb{R}^{3×3}\) 으로 주어지고 Depthmap(D)에 대해 \(D ∈ \mathbb{R}^{W×H}\) 으로 가정하면 관찰된 장면에 대한 포인트맵 X에 대해 아래처럼 구할 수 있습니다. $\(X_{i,j} = K^{−1} [iD_{i,j}, jD_{i,j},D_{i,j}]^⊤\)$
여기서 X는 카메라 좌표계로 표현.
카메라 m의 좌표계로 표현된 카메라 n의 pointmap \(X^n\)을 \(X^{n,m}\)으로 나타내고 수식(1)으로 정리하면 아래와 같습니다. $\(X^{n,m}=p_{m}p^{-1}_{n}h(X^n) \ \ (1)\)\( 추가로 \)p_m,p_n ∈ \mathbb{R}^{3×4}\(를 사용하면 이미지 \)n,m\(에 대한 world-to-camera pose을 취하고 \)h : (x,y,z) → (x, y, z, 1)$으로 동종 매핑이 수행됩니다.
Overview#
direct regression을 통해 generalized stereo case에 대한 3D reconstruction 작업을 수행하는 네트워크를 구축합니다.
direct regression: DCNN 등의 네트워크 모델을 통해 신체 부위의 키포인트 위치를 직접 피팅(regression)하는 방법.
네트워크 구축을 위해 RGB이미지 \(I^1,I^2 ∈ \mathbb{R}^{W×H×3}\)을 input으로 사용하고 결과로 연관된 confidence map \(C^{1,1},C^{2,1} ∈ \mathbb{R}^{W×H}\)와 함께 2개의 해당 point map \(X^{1,1},X^{2,1} ∈ \mathbb{R}^{W×H×3}\)을 출력합니다.
위 두 point map의 경우 \(I^1\)의 동일한 좌표계로 표현됨.
명확성과 일반화를 유지하기 위해 두 이미지의 해상도는 동일하다고 가정하지만 실제로는 해상도가 다를 수 있음.
Network architecture의 경우 CroCo 모델을 참고하여 구축하였습니다.
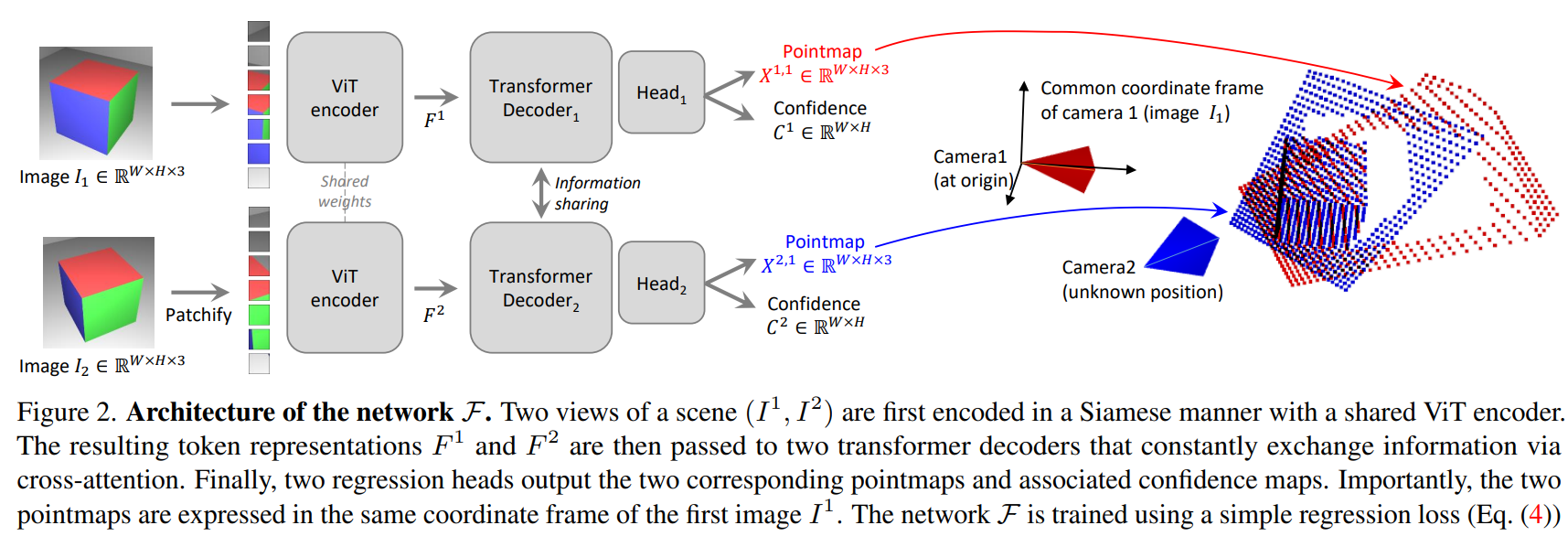 사진을 보면 각각 이미지 encodor, decoder 및 회귀 헤드로 구성된 두개의 동일한 branch(각 이미지 당 하나씩)로 구성됩니다.
사진을 보면 각각 이미지 encodor, decoder 및 회귀 헤드로 구성된 두개의 동일한 branch(각 이미지 당 하나씩)로 구성됩니다.
2개의 input이미지는 먼저 동일한 가중치를 공유하는 ViT 인코더로 인코딩되어 2개의 token representation(토큰 표현) \(F^1,F^2\)를 생성합니다.\( F^1 = Encoder(I^1),\ F^2 = Encoder(I^2)\) 디코더의 경우 CroCo와 마찬가지로 cross attention기능을 갖춘 generic transformer network입니다. 따라서 각 디코더 블록은 순차적으로 self-attention(뷰의 각 토큰이 동일한 뷰의 토큰에 참여)을 수행한 다음 교차 어텐션(뷰의 각 토큰이 다른 뷰의 다른 모든 토큰에 참여)을 수행하고 마지막으로 토큰을 MLP(Multi-Layer Perceptron)에 공급합니다.
중요! 디코더를 통과하는 중에 두 branch간에 정보는 지속적으로 공유됨. ; 정렬된 point map을 출력하는 데 중요.
여기서 \(DecoderBlock^v_i(G^1,G^2)\)는 \(v ∈ {1, 2}\) 분기의 i 번째 블록을 나타내며, \(G^1\) 및 \(G^2\)는 입력 토큰이고 \(G^2\)는 다른 branch의 토큰입니다.
마지막 과정으로 각 branch에서 별도의 회귀헤드가 디코더 토큰 세트를 가져와 각 pixel마다 포인트맵과 관련된 신뢰도 맵을 출력합니다.
Discussion#
위 과정에서는 출력 포인트맵을 얻었지만 축척 비율 문제와 기하학적 제약 부재에 대한 문제 발생 포인트 맵이 실제와 일치하지 않을 수 있으며, 네트워크가 특정 유형의 포인트맵만을 학습 가능
이를 해결하기 위해 축척 비율을 명확히 하고 기하학적 제약을 추가하는 등의 조치 가능
Training Objective#
DUSt3R 모델의 최종 학습 목표 confidence-weighted regression loss입니다. 기본적인 Loss 값은 3D공간에서의 회귀를 기반으로 Euclidean Distance를 통해 구할 수 있습니다. $\( ℓ_{regr}(v, i)= \left\|\left\|\frac{1}{z}X^{v,1}_i- \frac{1}{z}\bar{X}^{v,1}_i \right\|\right\| \ \ (2) \)\( 예측과 원본 데이터 사이의 scale ambiguity을 처리하기 위해, 배율인수 \)z = nor(X^{1,1}, X^{2,1})\( 과 \)bar{z} = norm(\bar{X}^{1,1}, \bar{X}^{2,1})$ 을 사용하여 예측 및 실측 포인트 맵을 정규화합니다.
각각 원점까지의 모든 유효한 지점의 평균 거리를 나타냅니다.
실제로는 논문에서 가정한 상황과 다른 경우를 가정하여 Confidence-aware loss를 추가하여 위에 Eq.(2)의 식에 적용하면 다음과 같은 식을 얻을 수 있습니다.
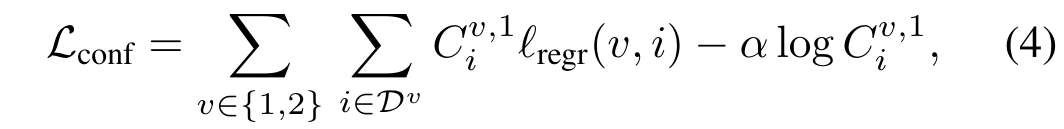
\(C^{v,1}_i\)은 픽셀 i에 대한 신뢰도 점수 / \(\alpha\)는 정규화를 제어하는 hyper-parameter(사용자가 직접 세팅해주는 값)
\(C^{v,1}_i = 1 + exp \ \tilde{C^{v,1}_i} > 1 \)로 정의하여 하나의 이미지에서만 나타나서 추정하기 어려운 3D point에 대해 추정 할 수 있도록 만듭니다.
Downstream Applications#
최종적으로 구현하고자 하는 application
Point Matching ; 두 이미지의 픽셀 간의 대응
nearest neighbor (NN) search을 통해 3D포인트맵 공간에서 관계 설정
이미지 \(I^1\)과 \(I^2\) 사이에 correspondence \(M_{1,2}\)를 만들어냄.
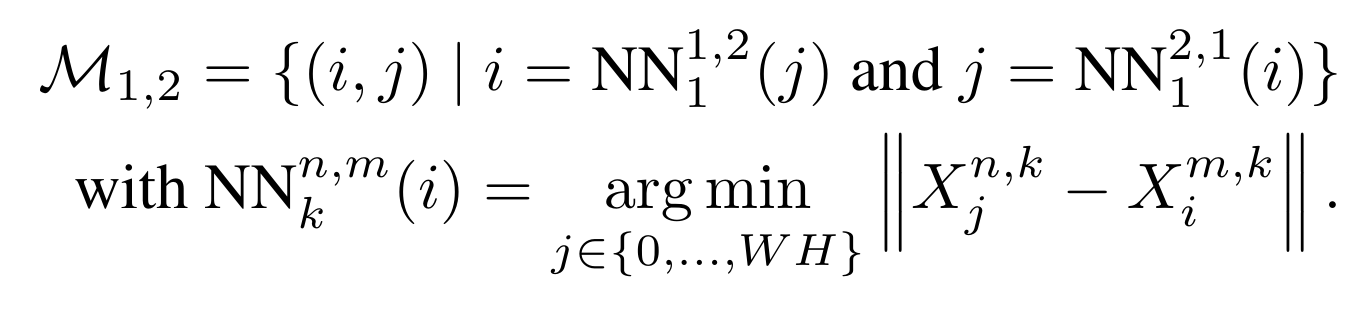
식을 자세히 살펴보면 k번째 view에서 바라본 n번째 view point i와 가장 가까운 m번째 view point를 각각 i 와 j로 찾고 양쪽 view에서 모두 성립할 경우에 2개의 pixel이 correspondence가 있다고 간주하게 됩니다. 결과적으로 3D 공간에 배치된 point가 가까운 것 끼리 correspondence를 갖게 됩니다.
Recovering intrinsics
intrinsic parameter (카메라 내부 변수) : intrinsic parameter의 종류에는 초점거리, 주점, 비대칭 계수 3가지가 있습니다. 각각 \((f_x,f_y),(c_x, c_y), skew_c = tan\alpha\)으로 나타내며 DUSt3R에서는 초점거리(focal length)만 추정하고 있습니다. 자세한 설명
DUSt3R 기본 모델로 pixel별 3D point를 예측했었습니다. 이 관계를 기반으로 아래 수식으로 focal length를 예측 할 수 있습니다.
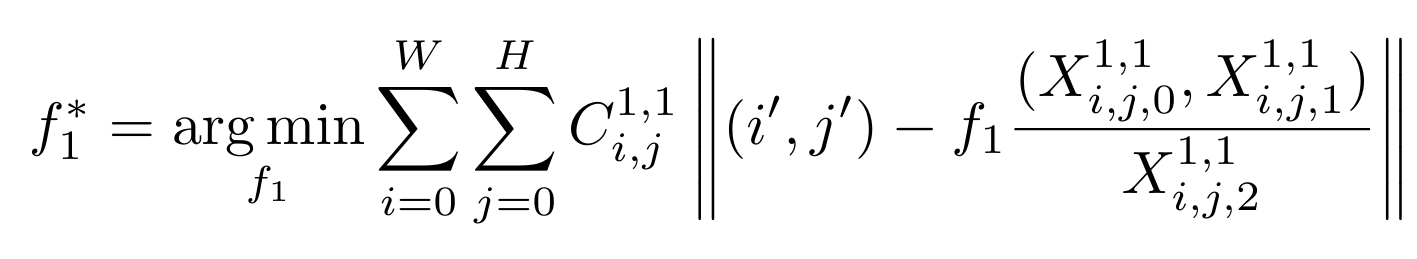
\(i',j'\)부분은 좌상단이 원점인 pixel 좌표계에서 이미지 중앙이 원점인 camera좌표계로 바꿔서 계산하기 위해, \(i'=i-\frac{W}{2} \ and \ j'=j-\frac{H}{2}\)를 해주게 됩니다. 그리고 가장 오른쪽 식은 해당 pixel에 해당하는 3D point의 x,y 좌표를 z값으로 나누어, 2D Image plane으로 projection되는 수식이 됩니다. 해당 수식이 최소값을 갖도록 만드는 focal length를 찾아주면, 2D 이미지와 3D point가 align 되게 됩니다. 이는 반복 최적화 문제로 풀게 되는데, 거리에 반비례하는 가중치로 추정값(=f)을 업데이트하는 Weiszfeld algorithm을 사용해서 해를 찾습니다.
Weiszfeld algorithm : 유클리드 공간에서 점 집합의 기하학적 L1 평균을 찾는 고전적인 알고리즘입니다.
Relative pose estimation
본 논문에서는 2가지 방법을 소개합니다.
첫번째 방식은 위에서 설명한 대로 2D매칭을 수행하고 Recovering intrinsics 수행 후 epipolar matrix와 relative pose를 추정하는 방법입니다.
두 번째 방식은 첫번째 방식보다 직접적인 방법으로 Procrustes alignment을 사용하여 포인트 맵을 비교하여 relative pose를 얻는 것입니다.
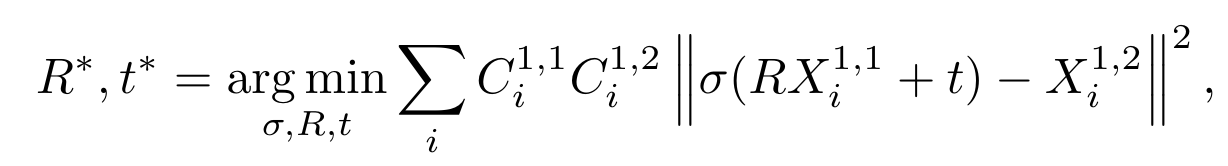 procrustes alignment알고리즘은 noise와 outlier에 민감하기 때문에 3D point cloud 정보와 2D feature point 정보를 알고 있을 때 카메라의 포즈를 구하는 PnP알고리즘과 데이터셋에서 노이즈를 제거하고 모델을 예측하는 RANSAC알고리즘을 사용해 위 수식의 해를 찾습니다.
procrustes alignment알고리즘은 noise와 outlier에 민감하기 때문에 3D point cloud 정보와 2D feature point 정보를 알고 있을 때 카메라의 포즈를 구하는 PnP알고리즘과 데이터셋에서 노이즈를 제거하고 모델을 예측하는 RANSAC알고리즘을 사용해 위 수식의 해를 찾습니다.
Absolute pose estimation
논문에선 visual localization이라고도 합니다. 이것도 두가지 방법이 있습니다.
첫번째 방식은 위에서 언급된 1) intrinsic을 추정하고, 2) 2D point matching을 추정하고, 3) PnP RANSAC으로 최적의 rotation, translation matrix를 찾습니다.
두 번째 방식은 ground-truth pointmap을 이미지를 제공하여, 위에서 언급한 relative pose estimation을 수행시에 해당 GT로 scale을 맞추는 방법입니다.
Global Alignment#
본 내용부터는 여러 이미지에서 예측된 pointmap을 joint 3D space로 alignment하는 방법에 대해 다룹니다.
Pairwise graph
이미지 세트 \( {I^1 , I^2 , . . . , I^N } \)주어진 장면에 대해, 먼저 N개의 이미지가 vertices V를 형성하는 연결 그래프 G(V, E)를 구성합니다. 각 모서리 \(e = (n, m) ∈ E\)는 이미지 \(I^n\)과 \(I^m\)이 일부 시각적 콘텐츠를 공유함을 나타냅니다. 이를 위해 우리는 기존의 기성 이미지 검색 방법을 사용하거나 네트워크 F(DUSt3r 네트워크)를 통해 모든 쌍을 전달하고 두 쌍의 평균 신뢰도를 기반으로 중복을 측정한 다음 신뢰도가 낮은 쌍을 필터링합니다.
Global optimization
우리는 연결 그래프 G를 사용하여 모든 카메라 n = 1… N에 대해 전체적으로 정렬된 포인트 맵 \({χ^n ∈ R^{W×H×3}}\)을 복구합니다. 이를 위해 먼저 각 이미지 쌍 \(e = (n, m) ∈ E\)에 대해 쌍별 포인트 맵 \(X^{n,n}, X^{m,n}\) 및 관련 신뢰도 맵 \(C^{n,n}, C^{m,n}을 예측합니다. 명확성을 위해 \)X^{n,e} := X^{n,n}\( 및 \)X^{m,e} := X^{m,n}\(을 정의하겠습니다. 우리의 목표는 공통 좌표 프레임에서 모든 쌍별 예측을 회전시키는 것이므로 쌍별 포즈 \)P_e ∈ R^{3×4}\(를 도입하고 각 쌍 \)e ∈ E\(와 관련된 스케일링 \)σe > 0$을 도입합니다. 그런 다음 다음과 같은 최적화 문제를 공식화합니다.
여기서는 표기법을 남용하여 v ∈ {n, m}에 대해 v ∈ e라고 씁니다. e = (n, m). 아이디어는 주어진 쌍 e에 대해 동일한 강성 변환 Pe가 두 포인트 맵 Xn,e 및 Xm,e를 모두 세계 좌표 포인트 맵 χn 및 χm과 정렬해야 한다는 것입니다. 왜냐하면 Xn,e 및 Xm,e는 정의에 따라 둘 다 표현되기 때문입니다. 동일한 좌표계에서. σe = 0, ∀e ∈ E인 사소한 최적을 피하기 위해 Qe σe = 1을 적용합니다.
recovering camera parameters
이 프레임워크를 직접 확장하면 모든 카메라 매개변수를 복구할 수 있습니다. 간단히 대체함으로써(즉, 식 (1)에서와 같이 표준 카메라 핀홀 모델을 적용함으로써) 모든 카메라 포즈 {Pn}, 관련 내장 함수 {Kn} 및 깊이 맵 {Dn}을 추정할 수 있습니다.
Discussion
global optimization method는 표준 gradient descent을 사용하여 3D 투영 오류를 최소화하는 데 중점을 둡니다.