MMhuman3D 프로젝트#
목표#
Real-time Multi Human 3D pose tracking을 통해 blender 내에서 실시간 Human modeling을 가능하게 하는 것
SMPL(Skinned Multi-Person Linear model)#
SMPL은 model이다. 따라서 input이 있으면 funtion과 같이 output을 도출한다.
Vertices? Mesh?#
vertices는 인체에 표면을 표현하는 점이다. 이러한 점을 모아 면을 만들면 polygon이라 칭하고, 이러한 면들을 집합을 Mesh라고 칭한다. 따라서 SMPL에서 3D mesh에 대한 의미는 인체의 피부라고 생각하면 편하다.
Input#
smpl input은 2가지이다.
pose parameters 72개 혹은 (24,3)으로 표현되는 파라미터이다. 관절(joint)의 의미적 표현을 가진다.
shape parameters 10개의 실수값(PCA coefficients)으로 구성된 shape vector로, 각 실수값은 신장(tall/short) 축과 같은 특정 축 방향에서 인체 오브젝트의 팽창/수축 정도 등으로 해석될 수 있다.
output#
3D Mesh 결론적으로 해당 모델은 특정 사람의 자세와 신체의 외형을 표현하는 3D Mesh가 출력으로 나오는데 이는 (6890, 3)의 3차원 좌표를 가진 6890개의 점으로 표현된다. 여기서 6890개는 신체의 표면을 구성하는 점 들이다.
Joint Location (24, 3) 관절의 좌표가 (x,y,z) 형태로 나오게 된다. 논문에서는 Joint 좌표가 24개가 아닌 23개로 카운팅을 했다. 이러한 이유는 골반(Pelvis)좌표를 root로 처리하거나 카운팅을 안하는 경우가 있기 때문에 23개로 카운팅을 했다.
SMPL 작동 원리#
pose estimation 모델이 image or video에서 인체 형태 정보 전달
입력 영상에 형태 정보로부터 Mesh를 구축한다.
구축된 Mesh를 토대로 관절(joint) 위치를 추정한다.
추정된 관절(joint) 위치를 기반으로 실제 포즈에 맞게 Mesh를 조정한다.

PARE(Part Attention Regressor for 3D Human Body Estimation)#
네트워크 구조 및 기능#
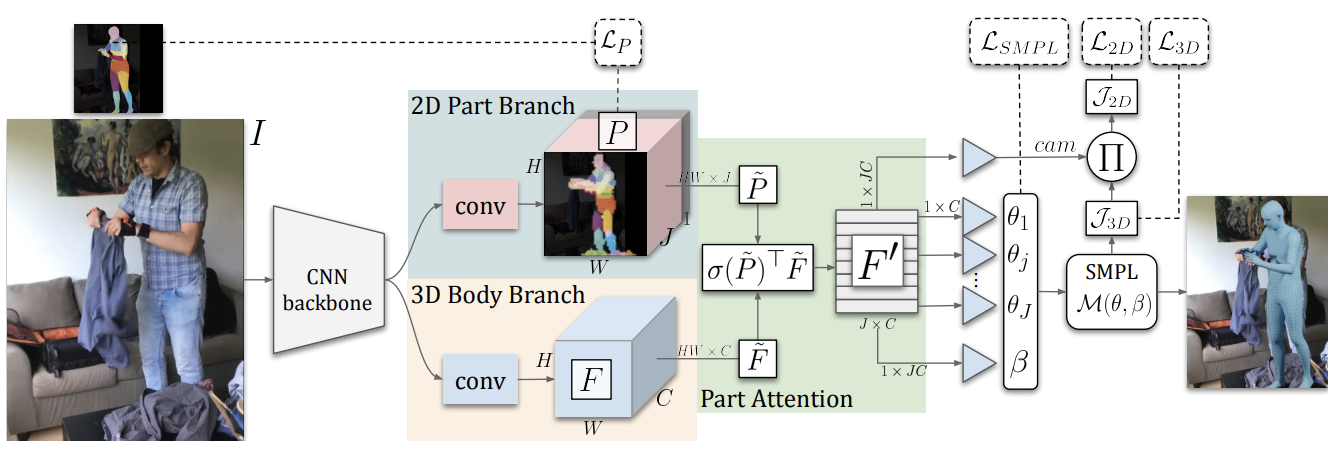
Part Attention Module: 이 모듈은 입력 이미지에서 신체의 각 부위를 식별하고 해당 부위에 대한 주의 맵을 생성한다. 이를 통해 네트워크는 신체의 중요한 부위에 더 많은 연산 자원을 집중할 수 있다.
3D Pose and Shape Regression: 주의 맵과 원본 이미지 정보를 조합하여 신체의 3D 포즈와 형태를 추정한다. 이 과정에서 3D 신체 모델이 사용되어 신체의 포즈와 형태를 수치화한다.
End-to-End Training: PARE는 하나의 네트워크 내에서 주의 맵 생성부터 3D 포즈와 형태의 추정까지 모든 과정을 처리한다. 이 방식은 전체 네트워크의 최적화를 도모하며 성능 향상을 이끈다.
Adaptive Loss Function: 다양한 손실 함수를 사용하여 포즈 추정의 정확도와 주의 맵의 효율성을 극대화한다.
주의(Attention) 메커니즘#
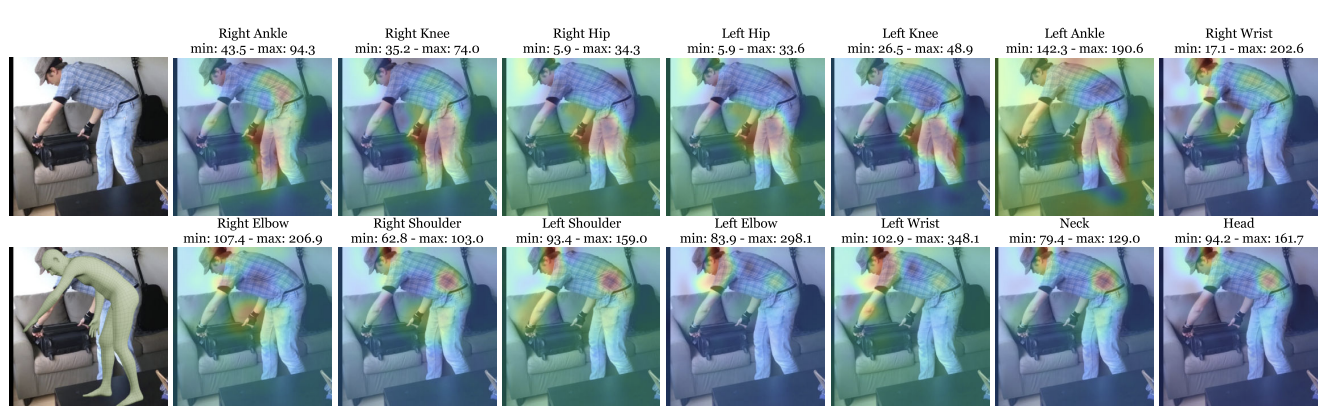
특징 추출: CNN을 사용하여 입력 이미지로부터 신체 관련 정보를 추출합니다. 이 과정에서 이미지의 중요한 패턴과 구조를 학습한다.
주의 메커니즘 적용: 추출된 정보에 주의 메커니즘을 적용하여 신체의 특정 부위에 집중한다. 이는 신체의 각 부위에 대한 주의 맵을 생성하여 모델이 중요한 부위에 더 많은 자원을 할당하도록 한다.
부위별 포즈 추정: 주의 맵을 활용하여 신체의 각 부위별로 포즈를 추정한다. 이는 모델이 특정 부위에 집중하여 보다 정확한 포즈 추정을 가능하게 한다.
최종 포즈 통합: 모델은 각 부위별 추정된 포즈 정보를 통합하여 전체적인 신체의 3D 포즈를 추정한다. 이는 신체의 구조적 연관성을 고려하여 자연스러운 포즈 추정을 지향한다.
How to work CNN and attention mechanism#
CNN#
PARE 모델에서는 주로 신체 관련 정보를 추출하기 위해 컨볼루션 신경망(Convolutional Neural Networks, CNN)을 활용한다. CNN은 이미지 처리와 패턴 인식에 매우 효과적인 딥러닝 모델 중 하나로, 여러 계층(layers)을 거치며 이미지의 저수준(low-level) 특징(예: 에지, 색상, 질감 등)부터 고수준(high-level) 특징(예: 신체 부위의 형태)까지 다양한 수준의 특징을 추출할 수 있다.
이 과정에서 CNN은 이미지의 원시 픽셀 값에서 시작하여, 각 컨볼루션 계층을 거쳐 가면서 점점 더 추상화된 특징을 학습한다. 최종적으로, 모델은 이미지 내에서 중요한 패턴과 구조, 즉 신체의 형태와 같은 정보를 추출해 내는 데 필요한 특징을 학습하게 된다.
Attention mechanism#
특징 추출 단계에서 얻은 정보를 바탕으로, PARE 모델은 주의 메커니즘(Attention Mechanism)을 적용하여 신체의 특정 부위에 집중한다. 주의 메커니즘은 모델이 전체 이미지 중 중요한 부분에 더욱 집중할 수 있도록 해주는 기술로, 특히 이미지나 시퀀스 데이터 처리에 널리 사용된다.
PARE 모델에서 주의 메커니즘은 신체의 각 부위에 대한 주의 맵(Attention Maps)을 생성한다. 이 주의 맵은 모델이 신체의 어느 부위를 중점적으로 보고 있는지를 나타내며, 신체의 각 부위별로 다른 가중치를 부여한다. 예를 들어, 어떤 이미지에서 팔의 움직임이 중요한 정보를 담고 있다면, 주의 메커니즘은 팔 부위에 더 높은 가중치를 부여하여 모델이 해당 부위에 더 집중하도록 한다.
이 과정을 통해, PARE 모델은 신체의 구체적인 부위나 특정 동작에 대한 정보를 더욱 정확하게 포착할 수 있다. 주의 메커니즘이 적용된 후, 모델은 각 신체 부위에 대해 더욱 집중하여, 그 부위의 포즈를 정확하게 추정할 수 있는 정보를 제공받게 된다. 이는 특히 신체 일부가 가려지거나 복잡한 배경 속에서도 신체 부위를 정확하게 인식하고 포즈를 추정하는 데 큰 도움이 된다.
Function of MMHuman3d#
MMHuman3Dv는 앞서 언급한 PARE, SMPL model을 사용하여 인체의 포즈 및 3D human modeling을 도와주는 벤치마크 툴이다. MMHuman3D의 정확도는 물론 MMHuman3D가 어느정도 영향을 끼친다. 하지만 PARE와 다른 모델을 쓰거나 다른 옵션의 모델을 쓰면 정확도가 달라질 것이다. 따라서 MMHuman3D는 모델을 통해 여러 방식으로 output을 도출하는 도구로 보면 편할 것이다.
Role of SMPL and PARE in MMHuman3d#
SMPL은 MMHuman3d에서 하는 역할은 PARE Model을 통해 pose estimate를 수행했을 때 Output은 SMPL Pose parameters 형태로 전달을 한다. 이러한 Parameters를 통해 SMPL human model 시각화를 하게 해준다. MMHuman3D에 Output으로 나온 데이터는 SMPL[body_pose, global_pose, beta]이다. Body_pose, Global_pose는 각각 SMPL pose parameters로 23개의 관절 또는 키포인트 좌표와 골반(Plevis) 좌표이다. Beta는 3D Mesh 형성하기위한 Shape parameter이다. 이 Parameter를 통해 체형 및 신장을 정한다. MMHuman3D에서 Male, Female, Natural SMPL model이 사용된다.
To do list#
MMHuman3D RTSP frame 처리 방식 현재는 frame 1개씩 받아서 바로바로 처리하는 방식 → ex) 1초에 8개의 frame 받고 동시에 8개를 처리하기
실시간 TCP 통신을 통해 blender에서 실시간 Human modeling
To do list No.1 result#
fps 1#

fps 8#
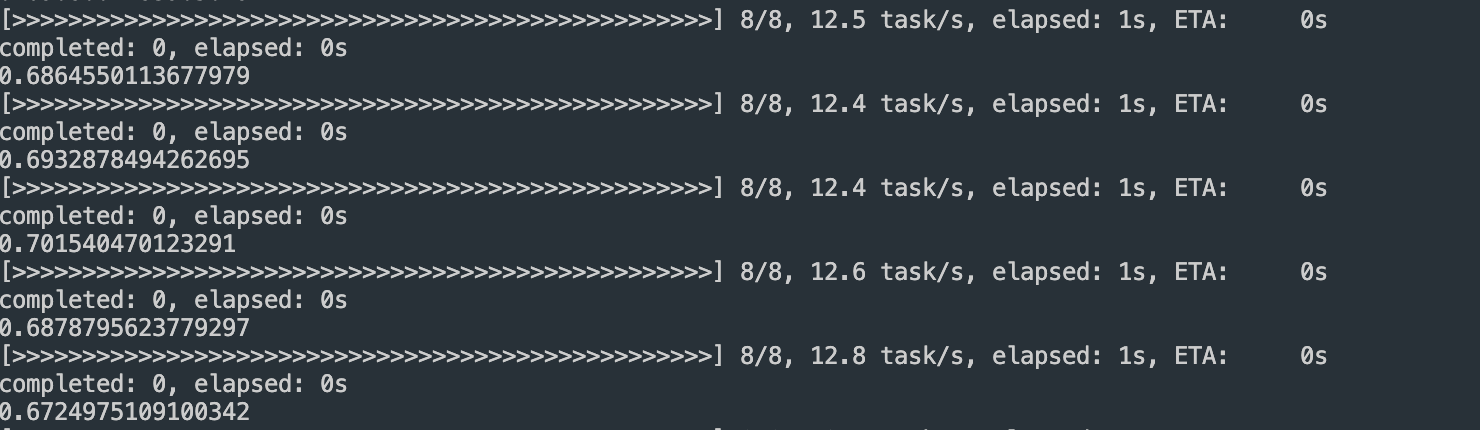
fps 10#
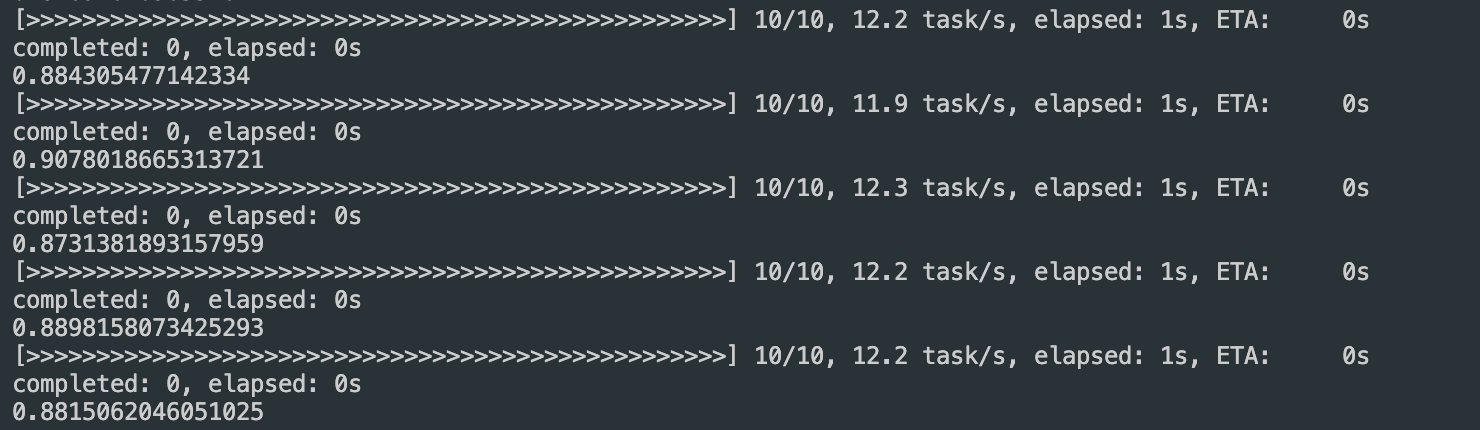
frame을 8장 처리와 10장 처리 과정 시간 계산
fps 1 → 0.2s for one time
fps 8 → 0.80~ 0.88s for one time
fps 10 → 1.01~1.09s for one time
frame 1개 프로세싱 소요 시간이 0.1초 예상 가능하다.
연산 시간 단축을 위한 해상도 줄이기#
앞서 말한 연구는 RTSP를 통해 Frame을 불러오는 것이다. RTSP에 기본 해상도는 1920 * 1080이다.
연산 시간을 단축하기 위해 해상도를 줄이는 방법이 있다.
Opencv
Opencv VideoCapture를 통해 RTSP를 불러오는 것이다. 따러 Opencv set 함수를 통해 설정함
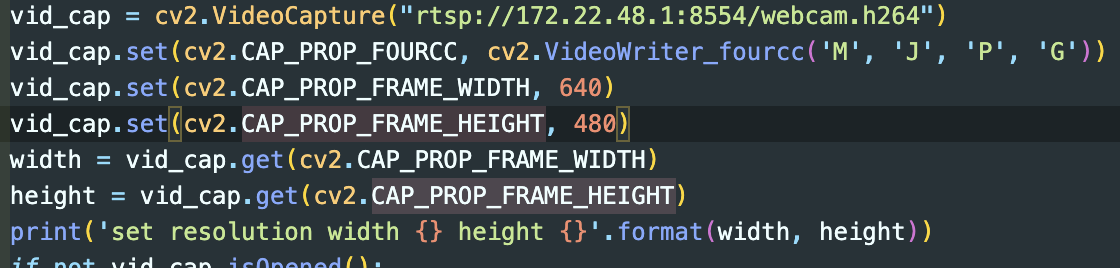 Width: 640 Height: 480 으로 설정
Width: 640 Height: 480 으로 설정
 set 함수로 해상도를 설정해도 바뀌지 않음
RTSP 해상도는 스트림 소스 측에서 특정 해상도로 전송하고 있을 경우, 클라이언트 측에서 해상도를 강제로 변경할 수 없다고 함
set 함수로 해상도를 설정해도 바뀌지 않음
RTSP 해상도는 스트림 소스 측에서 특정 해상도로 전송하고 있을 경우, 클라이언트 측에서 해상도를 강제로 변경할 수 없다고 함Opencv resize 함수를 통해 해상도를 강제로 변경 시도

Width: 640 Height: 480 으로 설정
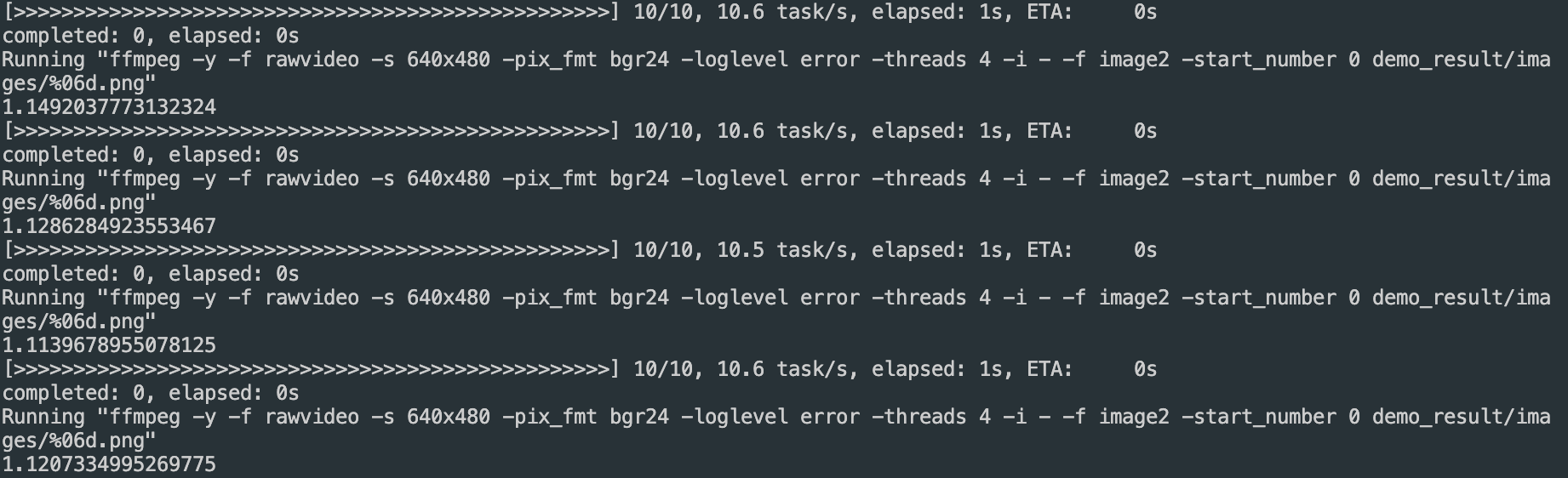
해상도가 바뀌긴 했지만 연산 속도가 이전보다 더 늦어진 것을 확인할 수 있음
RTSP
RTSP 스트림 소스측에서 전송할 때 해상도 옵션 변경
ffmpeg -f dshow -video_size 640x480 -i video="ABKO APC930 QHD WEBCAM" -framerate 30 -f rtsp -rtsp_transport udp rtsp://172.22.48.1:8554/webcam.h264
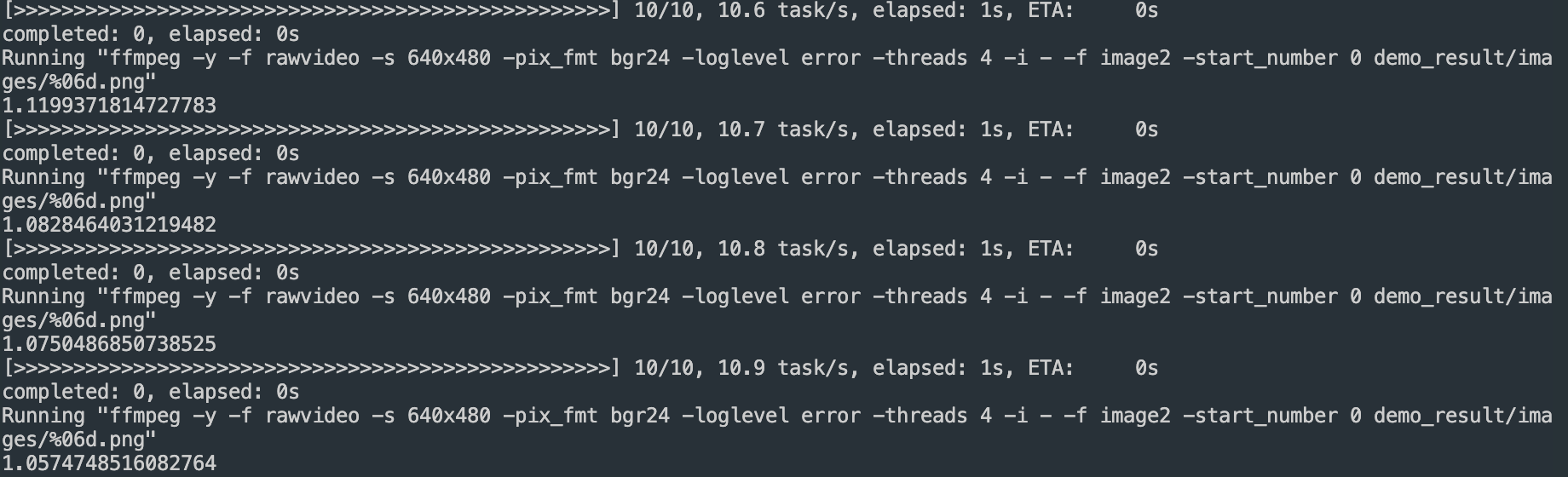 해상도를 변경해도 연산 시간이 똑같음
해상도를 변경해도 연산 시간이 똑같음
결론 Opencv resize함수를 통해 frame에 대한 해상도를 줄이면 loop에 연산이 추가가 되는 것이고 연산 시간은 늘어남. RTSP 스트림 측에 옵션을 통해 해상도를 줄여도 연산 시간은 똑같음.
Tracking model 연구#
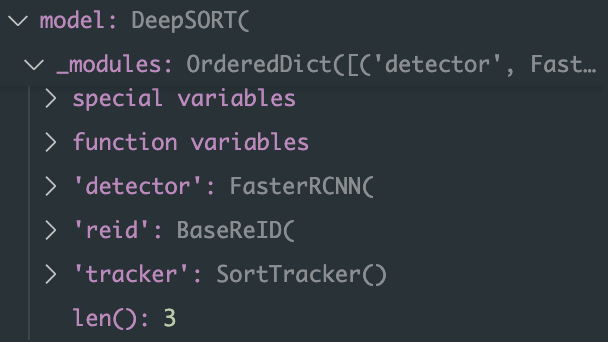
What is Tracking model? 쉽게 말해 Object detection을 진행하는데 필요한 model
Tracking model은 어떤 기능을 하는가? MMHuman3D에서 Pose estimation는 아무것도 없는 베이스 상태에서 이뤄지지 않는다. 먼저 Object detection을 바탕으로 특정 객체에 Pose estimation를 하는 것이다. Object tracking → Pose estimation → Human modeling
MMHuman3D에 사용되는 Tracking Model은 어떤 것인가? MMHuman3D에 사용되는 Tracking Model은DeepSORT란 모델이 사용된다.
DeepSORT란? DeepSORT = SORT + Deeplearning = (Kalman Filter + Hungraian Algorithm) + Feature Vector SORT = Kalman Filter + Hungraian Algorithm 이며, SORT에 Deeplearning Feature Vector더한 것이다.
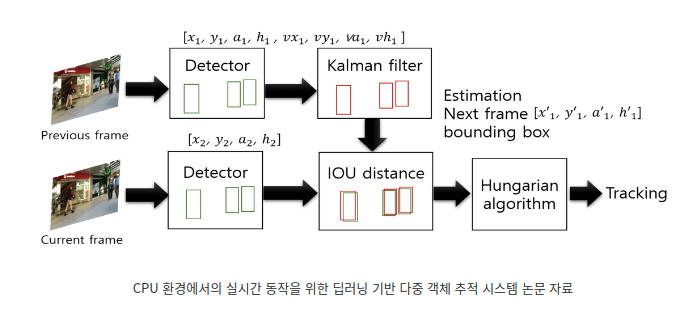
Kalman Filter?
이전 프레임(시점)의 bbox(detect된 객체의 경제box, bounding box)의 정보를 이용해 현재 프레임의 객체의 위치를 예측하는 것
Kalman Filter를 거치고 나온 정보(예측값)를 이용해 IOU distance를 구할 수 있고, 이를 Hungraian Algorithm으로 보내 객체 정보를 업데이트 할 수 있다.
IOU distance란? IOU란 Intersection over Union로 Object Detection 분야에서 예측 Bounding Box와 Ground Truth가 일치하는 정도를 0과 1 사이의 값으로 나타낸 값이다.
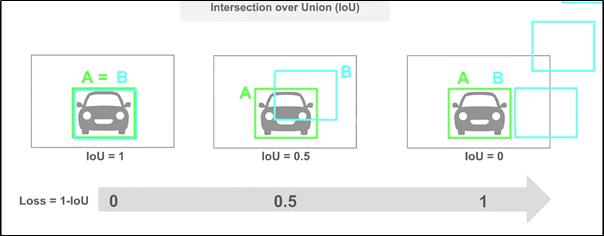
Hungraian Algorithm?
Kalman Filter에서 예측한 위치값과 실제 위치값의 IOU distance를 이용해 객체 정보를 업데이트
DeepSORT 과정
이전 프레임에서 객체를 가져와서(Detecter), Kalman Filter를 거쳐 예측값을 알아냄
현재 프레임에서 객체를 가져와서(Detecter), 1에서 구한 예측값과의 IOU distance를 구함
Hungraian Algorithm을 통해 Tracking 실행
Code use by the tracking model in MMHuman3D#
![]()
in def get_tracking_result
Bottom up? Top down?#
Top-down#
이미지에서 사람을 먼저 찾고, 찾은 사람의 Bounding Box에서 자세를 추정
사람을 먼저 찾고, 사람안에서 joint들을 찾기 때문에 정확도가 Bottom-up방식보다 높다
검출된 사람들을 순회하며 joint들을 찾기 때문에 속도가 Bottom-up방식보다 느리다
Bottom-up#
이미지에서 joint들을 먼저 찾고, joint들의 상관관계를 분석하여 이들을 연결하여 자세를 추정
정확도는 Top-down 방식에 비해 떨어지지만, Object Detection 과정이 없기 때문에 속도가 빨라 실시간 처리에 사용 가능
MMHuman3D → Top-down#
MMHuman3D pose estimation code#
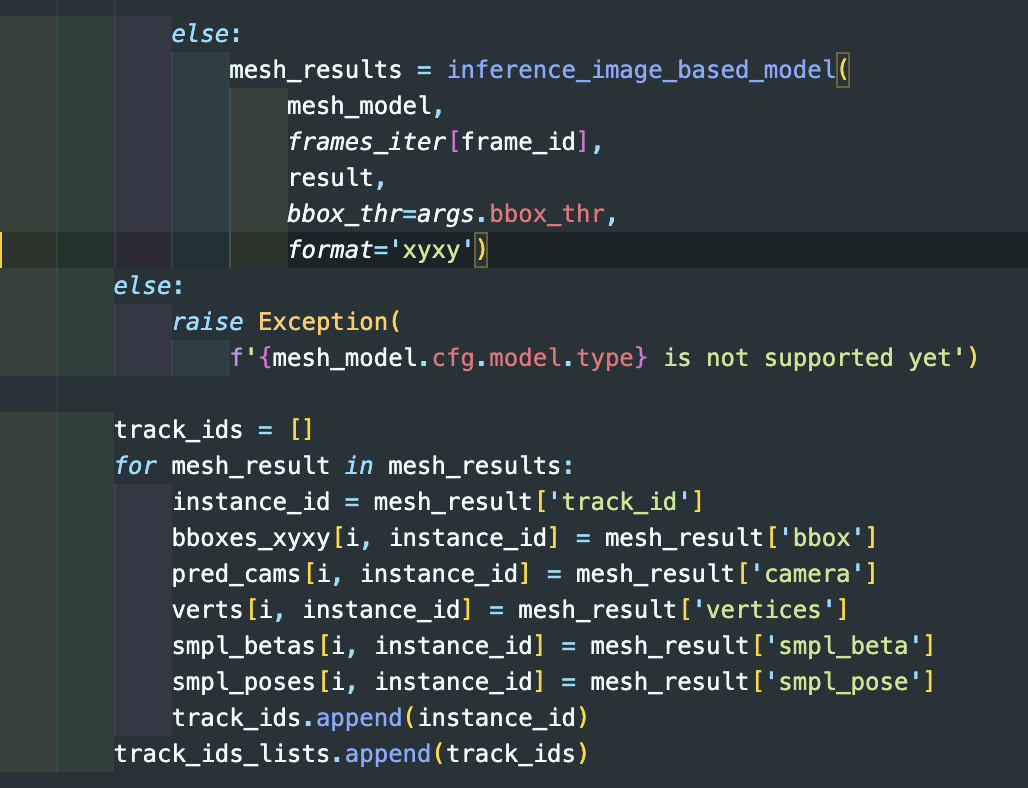
mesh model → PARE model
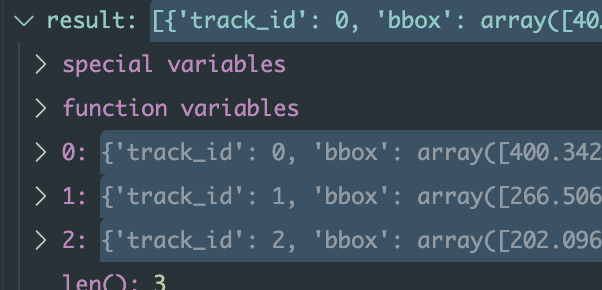
함수 inference_image_based_model에 parameter인 result는 bbox data
def inference_image_based_model#
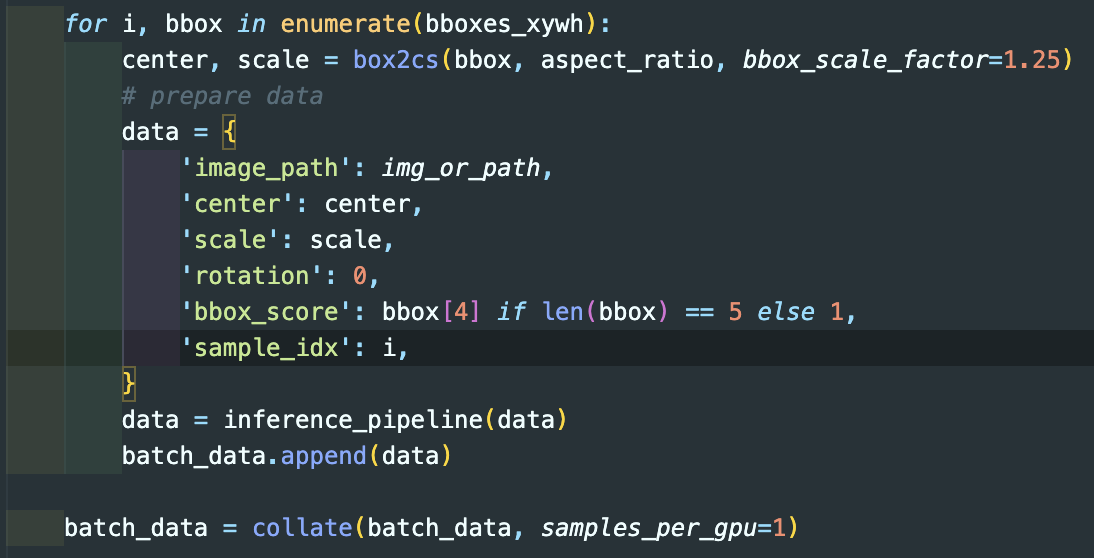
bboxes_xywh? det_results의 bbox data format(left, top, right, bottom) → format(left, top, right, high) 형태로 바꾼 것
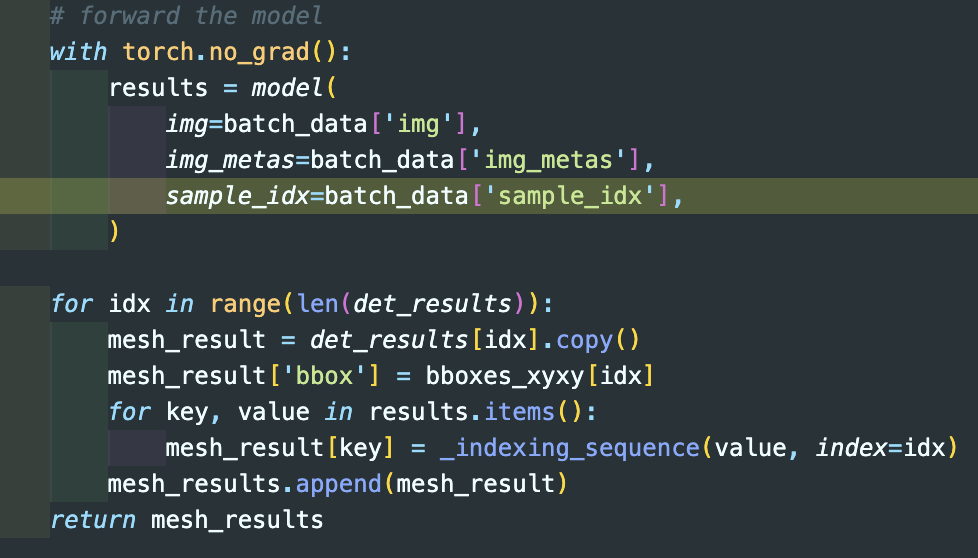
det_results는 def inference_image_based_model에 parameter result → bbox data